
Le projet ASM-COCO
Ancrage Sémantique Multimodal pour Cobots Conversationnel
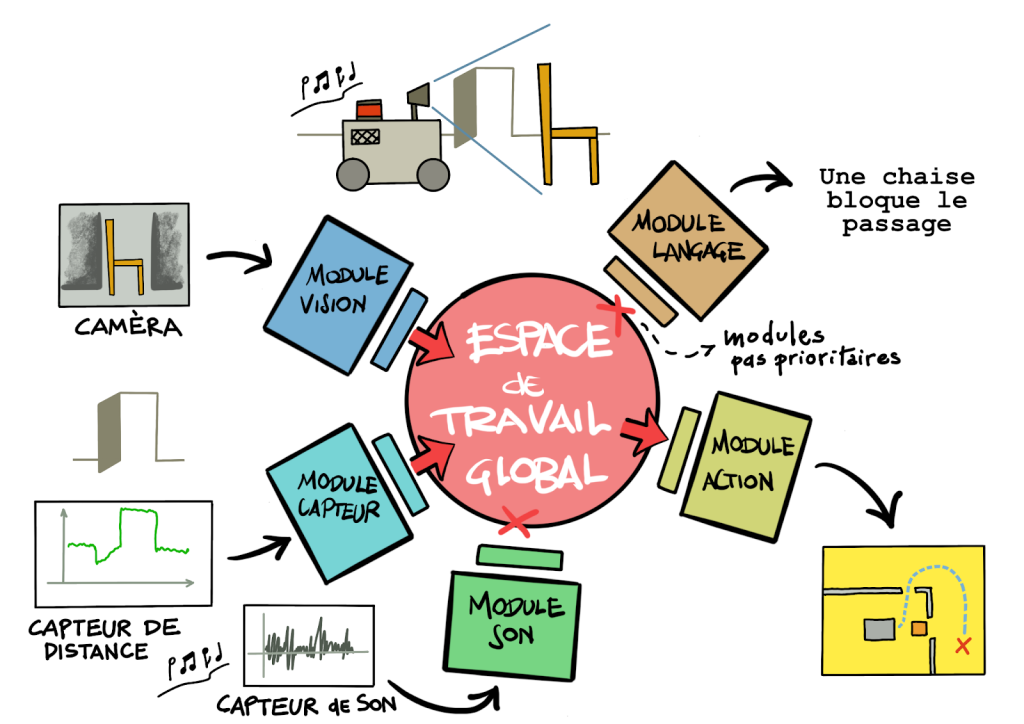
Comment permettre aux robots d’intégrer naturellement des informations multimodales pour agir intelligemment ? Cette thèse développe une architecture inspirée du cerveau humain qui fusionne plusieurs sources sensorielles dans un espace commun, permettant aux robots d’apprendre à naviguer et manipuler des objets de manière robuste.
Objectifs
- Implémenter un Global Latent Workspace (GLW) capable de fusionner des données visuelles, textuelles et sensorielles dans un espace latent amodal unifié
- Réaliser l’ancrage sémantique multimodal permettant au robot de créer des représentations internes du monde à partir de multiples sources d’information (caméras, capteurs, langage naturel)
- Intégrer un modèle de dialogue conversationnel permettant au robot d’interagir naturellement avec les opérateurs humains pour apprendre de nouvelles tâches
- Développer des capacités d’action autonome en reliant l’espace latent aux actions motrices du robot, soit par composition d’actions atomiques, soit par apprentissage par renforcement
- Permettre une programmation par la conversation sans expertise technique ni données d’entraînement massives, rendant les cobots accessibles aux opérateurs de terrain
Médiation scientifique
https://exploreur.univ-toulouse.fr/dans-la-tete-dun-robot : ASM-COCOType de financement
Thèse
Doctorante recrutée
Léopold Maytié
Référents
Rufin VanRullen
Nicholas Asher
Mots-clés
Apprentissage Profond, Ancrage Multimodal, Apprentissage par Renforcement,
Espace de Travail Global, Robotique
Dates
01/10/2022 au 31/12/2025
Tutelles
IRIT – Université de Toulouse
Site internet
Valorisation du projet
Résultats attendus
- Architecture GLW fonctionnelle : Un système opérationnel basé sur la théorie du Global Workspace capable de fusionner au minimum deux modalités (vision et langage), extensible à d’autres modalités (capteurs proprioceptifs, données de proximité)
- Capacités d’ancrage multimodal : Le robot peut associer des descriptions linguistiques (attributs puis phrases en langage naturel) à des perceptions visuelles, avec support de points de vue multiples (caméra fixe et caméra embarquée mobile)
- Interaction conversationnelle située : Intégration d’un modèle de dialogue permettant au robot de comprendre et exécuter des instructions en contexte, avec compréhension de son environnement immédiat
- Système d’action autonome : Capacité pour le robot de traduire les objectifs issus de l’espace latent en actions concrètes, soit par sélection d’actions prédéfinies, soit par apprentissage de politiques motrices
- Contributions méthodologiques : Utilisation de techniques innovantes basées sur la cycle-consistency réduisant la dépendance à la supervision, adaptées aux contraintes robotiques réelles
L’équipe

Nicholas Asher
ChercheurIRIT
Melodi
Traitement Automatique du Langage (TAL)